
Tactical Desktop Action 1.1.0 Release
Last updated: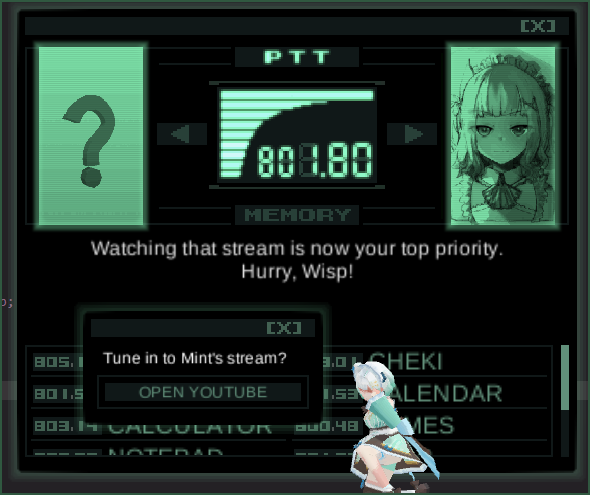
Happy birthday, Mint! This was a fun one to put together, with some features that I feel deliver real value.
Additions:
- YouTube Go-Live Alerts! Mint will CALL you on the Codec when she goes live. Never miss a stream again! There’s no excuse.
- Calendar and Event Alerts! Manage your calendar and get a CALL from Mint to remind you of your tasks for the day. You can even import and export .ICS files, offering full compatibility with most major calendar apps, such as Google Calendar!
Updates:
- The Clock can now select any time zone in the world. Yes, you can finally find out what time it is in the Fox Archipelago.
- The Music Player now supports lossless .FLAC files. Go wild, audio freaks.
Quality-of-(After)Life Fixes and Improvements:
- You can now opt to skip the intro/exit cutscenes on subsequent launches from the Settings menu.
- You can opt in and out of the YouTube and Calendar Alerts from the Settings menu as well.
- The application no longer suppresses OS notifications as though it were a normal full-screen window.
- The application now properly handles launching on secondary monitors (previously failed to calculate window borders).
If you find any bugs or have any feature requests, please let me know! The best way to reach me is via Email, but my DMs are open on most platforms, too!
Behind The Scenes
Now for the part of the blog post where I go in to excruciating detail about the work behind getting this update out the door. The new features might look rather mundane, but there was a lot of learning involved.
YouTube Alerts
A Brief Summary of Network Protocols: Socket To 'Em
In the world of networked systems, there are two major protocols for communication: HTTP and WebSocket. You are undoubtedly already familiar with the first, even if you have no engineering background!
With HTTP, the client makes a single request to an address, and then waits to receive a single response from the server. Great for transactional behavior, like asking for a web page!
Meanwhile, with WebSockets, the client makes a single request to an address, and then maintains a persistent connection to the server. This, in turn, allows the server to push information back to the client whenever, without needing to be asked for it first.
So, if you wanted to get notified every time a specific channel on the mega-giant streaming platform YouTube went live, which protocol do you think you'd want to use? WebSocket, right? Connect to the YouTube API server, provide it with a little information about what you're looking for, and then every time your channel went live, the server could proactively push a message to your client. Seems efficient and straightforward!
Wrong! YouTube doesn't have a WebSocket API. That would be too easy, too logical. Twitch does (called "EventSub"). But YouTube does not.
Okay, so if we can't get the server to reach out to us every time it has new information to share, and if we want up-to-the-second status updates, then we have to do HTTP Polling, which refers to the technique of making an HTTP request repeatedly at a high frequency, continually checking to see if the response has changed. This results in a lot of network traffic, most of which is effectively garbage. For example, if you polled an HTTP address every second of the day, that would be 86,400 requests, of which only one is likely to yield a response that you care about (the response which changed from "not live" to "live").
But, whatever, fine. We don't have a choice. If YouTube won't give us a WebSocket to connect to, surely they understand that this is the only alternative, and are therefore okay with us hitting their HTTP API with such volume.
Working Within Arbitrary Constraints: Fish Outta Quota
Wrong again! The YouTube API (and all Google APIs) have famously stingy quotas. By default, applications are allotted 10,000 Quota Units per day. The videos/list request, which, as the name suggests, can give us back status information about a list of videos, costs 1 Quota Unit. As established earlier, one request per second would come out to 86,400 requests per day, way above our quota. We can scale it back to one request per 10 seconds, bringing the total back down to 8,640 requests per day, and back below the quota.
Great! Now, what do we need to provide the videos/list request to get the information we need from it? Well, that would be a list of Video IDs. Not Channel IDs. Video IDs. So, how do we get a list of every Video ID that a channel has scheduled? Why, use the channels/list request, which also has a cost of 1 Quota Unit. And to be sure we pick up new Video IDs as soon as they're scheduled (for, say, guerrilla/unplanned streams), we would need to poll that address. Another 8,640 Quota Units spent, and suddenly we're back above our daily quota. Uh oh!
A natural solution here would just be to further decrease the frequency of the polling mechanisms. Fortunately, there is another, less-documented way. Turns out, YouTube channels all have RSS Feeds (as does this very website!). Accessing this RSS feed does not go through the API, and therefore does not consume Quota Units.
For example, we can hit up the address https://www.youtube.com/feeds/videos.xml?channel_id=UCr5N4CrcoegFpm7fR5a_ORg to get a list of my most recent dozen-or-so videos. If I were streaming on YouTube, this list would also include upcoming scheduled streams. So, from this document, we can pluck out the most recent Video IDs for a channel for free, and then poll the videos/list request at our desired frequency as originally planned. Now, what do we do with this information?
Righting the Wrongs: Doing It Ourselves
Since YouTube won't give us one, we'll just make our own WebSocket server. As established, a single poller checking for video status every 10 seconds consumes nearly the entire daily quota, so it is completely infeasible to have every individual instance of "Tactical Desktop Action" do its own polling. Instead, they all connect to a central WebSocket server that I've deployed here on skeletom.net. The singular server handles the polling, and dispatches stream information to clients once when they connect to the socket, and then again whenever there is a status update. In this way, we can handle an extremely high and variable number of clients while maintaining a fixed quota consumption.
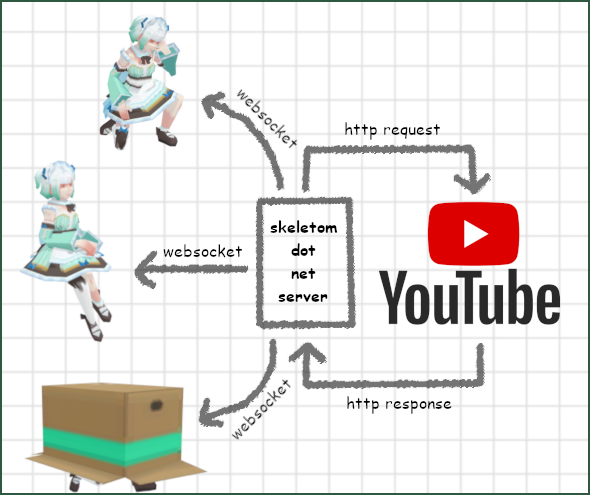
A diagram illustrating how our web server can handle many clients without increasing YouTube API quota consumption.**
Once I got this up and running for Mint's channel, I began thinking about a design pattern that would let me expand this coverage to more channels. After all, I have made quite a few desktop toys and it would be nice to eventually backport this feature to all of them. The good news is, that for all of its shortcomings, the YouTube API does permit you to batch your requests together to save on quota. That is to say, we can include Video IDs from multiple channels in our videos/list request.
With this knowledge in mind, I designed a system with a central polling engine that fires at a fixed frequency, which contains a map linking Channel IDs to callback functions. The system goes through the list of Channel IDs, queries their RSS feeds, and populates a list of Video IDs for each Channel ID. This allows us to remember previous the status of each video, and also allows us to link Video IDs back to specific Channels. We can then poll for status of all desired channels in a single batch. When a given Video ID finally goes from being offline to being live, we can easily find which Channel ID it belongs to, and therefore which callback function to execute. In this specific example, the callback is "notify all WebSocket clients who care about this channel with a structured message", but with the way the system is designed, it could be anything you'd like.
This is a system I am proud of. You can check out the full implementation on GitHub, if you'd like.
Calendars
.ICS: 1998 Sends Its Regards
Like all good standards on the internet, the iCalendar (.ICS) format was designed in the 1990s, by the noble Internet Engineering Task Force as a universal means of communicating schedule information. In the modern age, you'd have to imagine that every calendar vendor would instead try to introduce their own proprietary format. But the '90s were a different time. And no, despite what you may think, the format has nothing to do with Apple or the iPod (which would not hit the market until three years later).
Anyway, ICS is simple and text-based. But it's not XML (which was also invented in 1998), and it's not JSON (which was invented in 1999), it's a third thing!
An extremely minimal ICS file looks something like this:
BEGIN:VCALENDAR
VERSION:2.0
PRODID:-//Google Inc//Google Calendar 70.9054//EN
BEGIN:VEVENT
UID:123-ABC-456
DTSTART:20050228T100000Z
SUMMARY:Dog-sledding Practice
END:VEVENT
END:VCALENDAR
A calendar with a single event, titled "Dog-sledding Practice", which occurs on February 28th, 2005 at 10 AM GMT.
Similarly to XML, the ICS format features verbose start and end tags for components (here denoted with BEGIN: and END:), and can also feature components nested within each other (for example, the VEVENT component is nested within a VCALENDAR). Properties are presented in KEY:VALUE pairs (for example, the VERSION property has a value of 2.0). Because this is a specialty format used only for this one thing, modern programming languages don't ship with parsers for ICS, as they often do for XML and JSON (which are usage-agnostic, general purpose formats).
That's fine, though. Seems simple enough to write our own parser for, right? Just split the file on line breaks, and split the lines on colons. Every time you hit a new BEGIN: tag, store all subsequent properties in a new component until you hit an END: tag.
Well, not quite. The IETF decided that no individual line of an ICS file may exceed 75 octets (8 bits). Apparently, this was done because some contemporary systems of the era were so memory-bound that they could not handle longer lines. The '90s were a different time, indeed. So what do you do if you have a line that needs to be longer? You "fold" it.
DESCRIPTION:This is a long description that exists on a long line.
Becomes…
DESCRIPTION:This is a lo
ng description
that exists on a long line.
Thus, to "unfold", you must search for leading whitespace on a line, and, if present, append that line the the prior line, removing the whitespace. I used a RegEx for this. Your mileage may vary. But, once we unfold, we can finally parse line-by-line.
Next, we need to know that properties may also have parameters, in addition to their values. These are denoted by a leading semicolon, a parameter name, an equal sign, and a parameter value, like so:
DTSTART:20060228T100000;TZID=America/New_York
A start time with a Time Zone ID specified.
Lastly, we need to know that property values and property parameters can occur in any order. For example, this property also valid and is functionally identical to the prior one:
DTSTART;TZID=America/New_York:20060228T100000
A start time with a Time Zone ID specified, in an alternate order.
With all of this knowledge, we can finally assemble our data model for ICS. Each pair of BEGIN: and END: tags forms a component object, which itself contains a list of nested component objects and a list of property objects. Each unfolded line that isn't a BEGIN: or END: tag becomes one of those property objects, which contains a Value string, as well as a map of string-to-string parameter pairs.
The Loathsome RRULE: Do It Again
Unfortunately, there's one property that kind of breaks the established patterns. And it's an important one. It's called the RRULE, or "Recurrence Rule".
These rules are somewhat intuitive to read for a human, but are surprisingly complex for a machine. Let's write a rule to make our event recur every day in February in 2005 and 2006.
RRULE:FREQ=DAILY;UNTIL=20060228T100000Z;BYMONTH=2
Every day, in Month 2, until February 28th, 2006.
Or…
RRULE:FREQ=YEARLY;UNTIL=20060228T100000Z;
BYMONTH=2;BYDAY=SU,MO,TU,WE,TH,FR,SA
Every year, in Month 2, on Sunday, Monday, Tuesday, Wednesday, Thursday, Friday and Saturday, until February 28th, 2006.
Or…
RRULE:FREQ=MONTHLY;UNTIL=20060228T100000Z;
INTERVAL=12;BYDAY=SU,MO,TU,WE,TH,FR,SA
Every 12 months, on Sunday, Monday, Tuesday, Wednesday, Thursday, Friday and Saturday, until February 28th, 2006.
Or… Well, I could go on and on. But hey, did you notice that?
RRULE:FREQ=MONTHLY;
Huh? Why is the value of an RRULE formatted like a parameter? That throws our whole parsing process into disarray. It's particularly confusing because, according to the iCalendar guidelines, the only valid value types for the RRULE are frequencies. So why specify that the value is a frequency at all?
Anyway, once we fix our parsing to account for that, we still have to actually interpret the meaning of the RRULE. This was tricky for me to wrap my head around, so I'll do my best to summarize.
Because an RRULE can potentially recur forever, we can't simply pre-process them to generate a definitive list of all recurrences for every event when loading a calendar. Instead, they need to be evaluated within the scope of a RANGE_START date and a RANGE_END date, which is fine, because a calendar is only ever viewed in slices anyway, be they weeks, months, or years. Once we define those bounds, we can take the following steps:
- Generate list of all potential dates.
- Start with your first occurrence date (
DTSTARTproperty) and extend a number of days based on theFREQvalue. For example, aWEEKLYfrequency would extend 7 days from the first occurrence. - Jump ahead to the next start date by multiplying the frequency by the
INTERVALparameter, if it exists. For example, aWEEKLYfrequency withINTERVAL=2would advance 14 days (7 days * 2 intervals) from the previous start date. - Repeat this process until the next start date is later than the
RANGE_ENDdate specified by our evaluation range.
- Start with your first occurrence date (
- Apply default values to our filters if needed.
- If the rule is of
WEEKLYfrequency and does not specify aBYDAY,BYWEEK,BYMONTHDAYorBYMONTHparameter, add the day of the week of theDTSTARTdate toBYDAY. - If the rule is less frequent than
WEEKLYand does not specify aBYDAY,BYWEEK,BYMONTHDAYorBYMONTHparameter, add the day of the month of theDTSTARTdate toBYMONTHDAY. - If the rule is less frequent than
MONTHLYand does not specify aBYWEEKorBYMONTHparameter, add the month of theDTSTARTdate toBYMONTH.
- If the rule is of
- Begin pruning the list of potential dates based on filter criteria.
- If the
BYMONTHparameter is present, remove potential dates that are not within the listed months. - If the
BYYEARDAYparameter is present, remove potential dates that are not on the listed days of the year. - If the
BYMONTHDAYparameter is present, remove potential dates that are not on the listed days of the month. - If the
BYDAYparameter is present, remove potential dates that are not on the listed days of the week. - If the
COUNTparameter is present, trim the list of potential dates to match the given length. - If the
UNTILparameter is present, remove all potential dates that occur after the given date. - Finally, remove all potential dates that occur before our
RANGE_STARTor after ourRANGE_ENDdates.
- If the
And there you have it! The resulting list of dates represent every occurrence of the event within the desired range. I'm sure there's room for optimization, but despite what all this work with the format may have you thinking, we're not actually in the '90s any more! We can afford the computational overhead (but I will continue to think about ways to optimize when making updates).
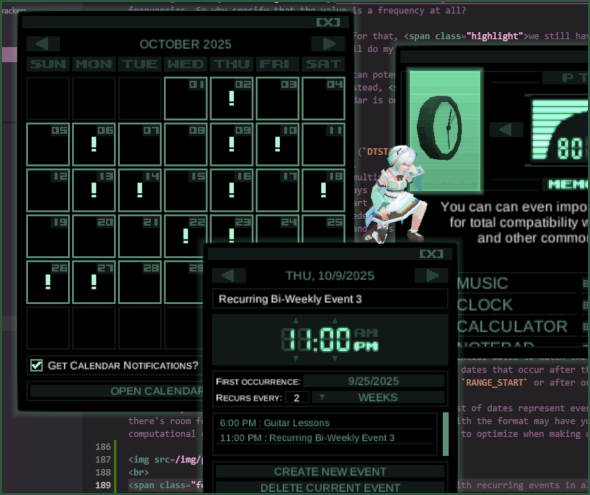
A calendar with recurring events in all of its glory.
Why Didn't You Just Use ical.NET?
Listen. I don't make these toys just to show off and impress my idols, I also make them to improve my design and engineering skills, While there is a robust, existing, open-source C# library for ICS parsing called ical.NET, I encountered a few problems with it:
- It required a version of C# newer than what my version of Unity supported.
- I wouldn't gain any problem-solving skills from using it!
While all the aforementioned complexities certainly vexed me, I was genuinely very interested to write my own parser. I don't get to work on pure algorithms too often, and this one dealt with recursion (for nested components), which is always a little daunting to think about. The resulting system is tailored to support the specific needs of my application, while also being lightweight enough for me to debug by myself. Much like the YouTube notifier, I am proud of it. I think it's some of my best work to date. And that, to me, is what really counts. Not just production speed, but personal growth.
Closing Remarks
I genuinely cannot fathom why anyone would reach the end of this article organically, but thank you for doing so. As hinted at by the end of the release trailer, I have yet another big update planned for "Tactical Desktop Action", this one featuring mini-games. And hopefully good ones at that! Please look forward to them, ideally releasing sooner than Mint's next birthday.
If you got this far, please ping me with the phrase "I READ THE TACTICAL DESKTOP ACTION 1.1.0 RELEASE NOTES AND ALL I GOT WAS THIS LOUSY COMMAND." on any platform of your choosing. Hell, even Email me. It's fine.
Ciao!

